Project Overview
CUDA ELM Feature Extraction Benchmark is a modern reboot of an academic project into a practical GPU benchmarking toolkit for Extreme Learning Machines. It focuses on feature extraction plus classification with shallow, closed-form models that can be trained far faster than many deep networks while still achieving competitive accuracy in real-world tasks.
The project provides a C++20 and CUDA 13.x core for batch and online ELM variants, wrapped in a reproducible, Docker-only workflow with clear tests, benchmarks, and demos. Researchers can treat it as a baseline for experimenting with online sequential ELM, hierarchical ELM, and RBF-based feature maps on modern GPUs, or as a reference for writing testable CUDA code and performance tooling around ELM-style models.
Features
- GPU-accelerated ELM variants: Implements core batch ELM and Online Sequential ELM (OS‑ELM) with additive and RBF hidden nodes, targeting scenarios where closed-form training and fast retraining are more important than deep network depth.
- Advanced online and hierarchical models: Extensible design for constrained OS‑ELM (OS‑CELM) and Hierarchical OS‑ELM (H‑OS‑ELM) so you can explore online feature hierarchies and RBF-based hidden layers without rewriting the core training loop.
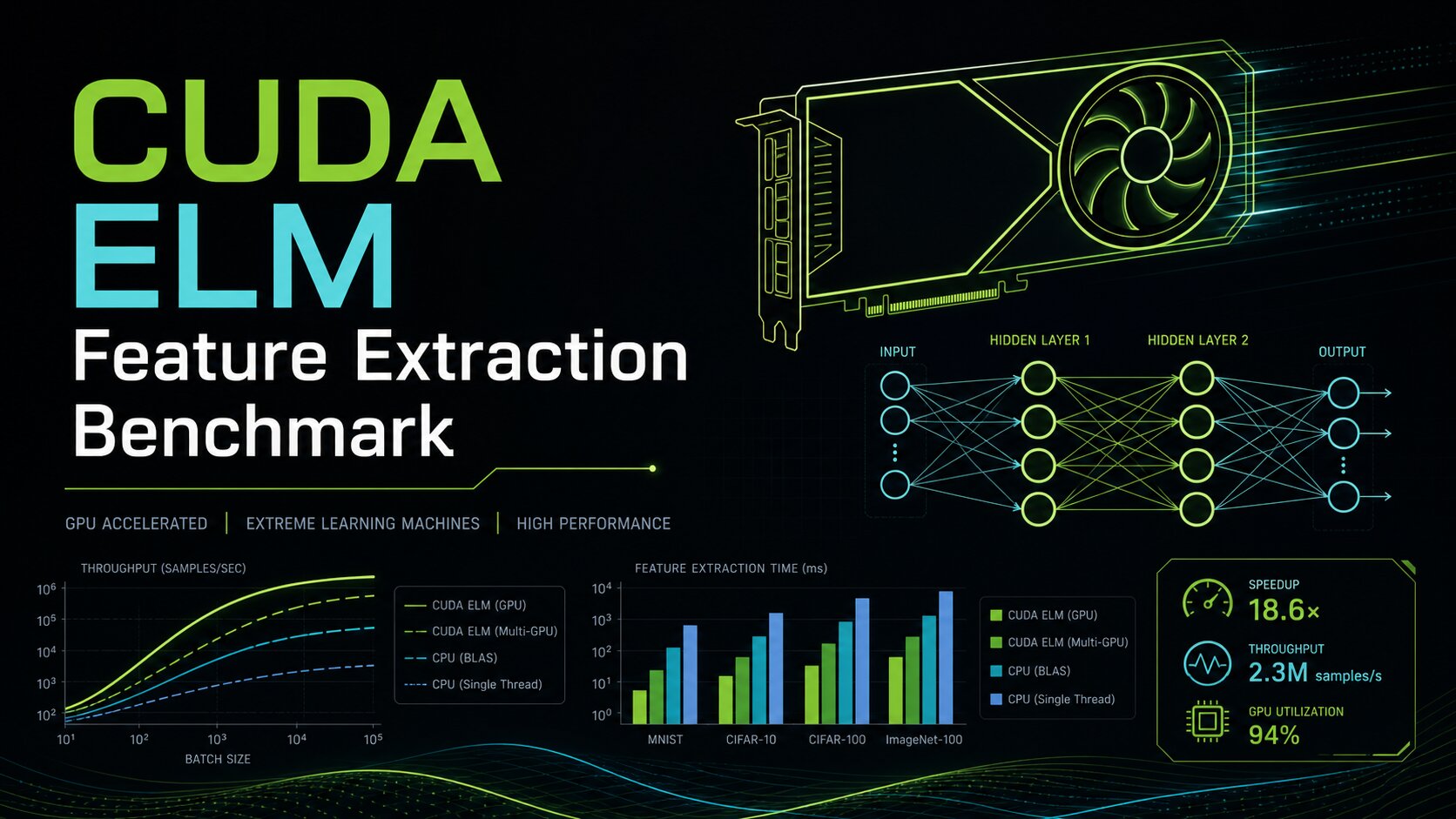
- Reproducible GPU benchmarks: Built-in Google Benchmark microbenchmarks for key CPU and GPU paths (hidden layer construction, least-squares solves, RBF feature maps) that emit JSON for comparison over time and for visualization in the demo frontend.
- Docker-only, test-driven workflow: All builds, tests, and benchmarks run inside CUDA-enabled Docker images, with GoogleTest/CTest and clang-format/clang-tidy wired into the dev container to keep the codebase consistent and verifiable.
- Interactive demos with benchmark views: Separate GPU and CPU demo images expose a small API and UI for running ELM experiments and inspecting benchmark snapshots or on-demand runs, so it’s easy to compare CPU vs GPU performance and different model variants.
- Researcher-friendly docs: A getting-started guide, algorithm notes, and Mermaid diagrams cover architecture, dataflows, and the tech stack, so researchers can quickly orient themselves and plug in new datasets, loss functions, or ELM variants.
Tech Stack
Core Algorithms and Runtime
- Language: C++20 for the core library and host logic
- ELM variants: Batch ELM, OS‑ELM, OS‑CELM, and scaffolding for H‑OS‑ELM with additive and RBF hidden nodes, following the unified OS‑ELM framework for both activation types.
- Linear algebra: cuBLAS and cuSOLVER for GPU-accelerated dense operations and least-squares solves; standard BLAS/LAPACK equivalents on CPU where appropriate.
- Randomization: cuRAND and C++ standard library RNGs for reproducible initialization of hidden-layer weights, centers, and biases.
CUDA, Design, and Tooling
- CUDA: CUDA 13.x Toolkit targeting recent NVIDIA GPUs via official
nvidia/cuda:*‑develimages. - Kernels: Small, composable CUDA kernels and device functions, designed according to NVIDIA’s best-practices for memory access, occupancy, and testability.
- Memory and resources: RAII wrappers around device buffers, streams, and cuBLAS/cuSOLVER handles to keep resource management explicit and safe.
- Style and static analysis: clang-format as the single source of truth for formatting and clang-tidy for static analysis, both running inside the dev container.
Benchmarks and Profiling
- Microbenchmarking: Google Benchmark suites for CPU and GPU paths, with JSON output used for offline comparison and feeding the demo frontend.
- Profiling: NVIDIA Nsight Systems and Nsight Compute included in the dev image for deeper kernel-level and timeline profiling during performance work.
Demos and Documentation
- GPU demo: CUDA-enabled Docker image exposing an API and UI (FastAPI/Gradio or notebook-based) for running GPU-backed ELM experiments and triggering small on-demand benchmarks.
- CPU-only demo: Lightweight image for free-tier hosting that uses the CPU backend with the same API shape and benchmark snapshots baked in.
- Docs site: GitHub Pages documentation at
e-choness.github.io/feature_extraction_cuda_elm, including a getting-started guide and architecture notes for researchers who want a guided path into the codebase.
Infrastructure
- Build and tests: CMake ≥ 3.22, CTest, GoogleTest, and Google Benchmark, all executed via Docker Compose.
- Containerization: Dedicated Dockerfiles for development, GPU demo, and CPU demo, with NVIDIA Container Toolkit used to attach host GPUs when available.
- CI-ready: Style and test commands designed to run non-interactively (e.g.
ctest,scripts/style_check.sh,scripts/run_benchmarks.sh), making it straightforward to plug the project into GitHub Actions or similar systems.